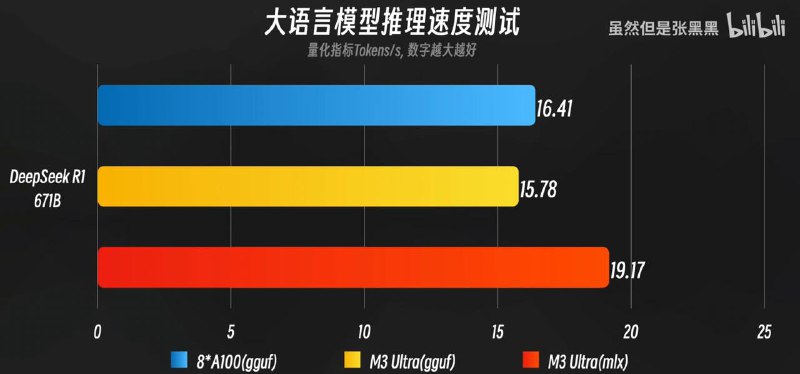
综合各家测试结果,满血M3 Ultra运行 R1 671B 4bit量化版:GGUF框架下15.78 tokens/s,MLX框架下19.17 tokens/s,整机功耗约60w。在短序列生成场景中,其持续输出速率接近8张A100(FP16精度)集群的基准表现。
当前QwQ 32B测试结果约20 tokens/s(量化版),在线版本因采用更高精度计算和复杂提示工程,实际体验可能优于本地量化部署。
张黑黑 | 小白测评 | Flypig
📮投稿 ☘️频道 🌸聊天 🗞𝕏
👍 320 🤨 45 ❤️ 16 👎 11 🔥 10 😁 8 🤪 4 😐 3